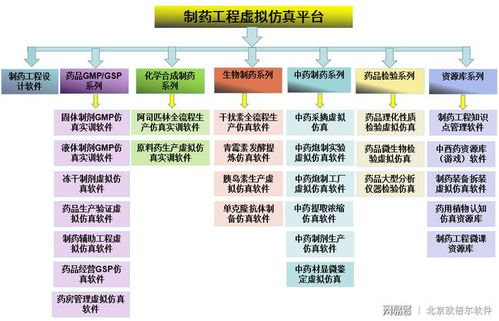
基于火龙果软件工程的网络工程大数据应用 数据探查与发现系统的开发实践
引言:大数据时代的网络工程挑战
在当今数字化时代,网络工程领域产生的数据量呈指数级增长,从网络流量日志、设备状态监控到用户行为记录,这些海量、多样、高速的数据构成了网络运维与优化的核心资源。传统的数据处理方法已难以应对,因此,开发一个专门的大数据应用程序来执行数据探查与发现,成为提升网络工程智能化水平的关键。本文将结合“火龙果软件工程”的开发理念,探讨如何构建这样一个系统。
一、项目目标与核心功能
本项目旨在开发一个大数据应用程序,专注于网络工程环境下的数据探查与发现。核心功能包括:
- 多源数据集成:支持从各类网络设备(如路由器、交换机、防火墙)、服务器、传感器及云端平台自动采集数据,实现结构化与非结构化数据的统一接入。
- 智能数据探查:利用数据挖掘与机器学习算法,自动识别数据模式、异常点、关联关系及趋势。例如,通过时序分析检测网络流量突变,或通过聚类发现用户行为群体。
- 交互式可视化发现:提供丰富的图表、仪表盘及地理信息映射,允许工程师通过拖拽、筛选等操作,直观探索数据,快速定位问题或洞察。
- 自动化报告生成:基于探查结果,自动生成数据质量报告、性能分析报告及安全威胁简报,支持定制化输出。
二、火龙果软件工程方法的应用
“火龙果软件工程”强调敏捷、迭代与用户协同。在本项目中,我们将其原则融入开发流程:
- 迭代开发:采用敏捷开发模式,将系统划分为数据采集层、处理层、分析层和展示层,每层通过短周期迭代逐步完善,确保快速响应需求变化。
- 用户参与设计:邀请网络工程师作为核心用户,全程参与原型设计、功能测试及反馈循环,确保工具贴合实际工作场景,如针对网络故障排查的特定探查需求。
- 持续集成与测试:建立自动化流水线,集成单元测试、性能测试及数据验证测试,保障系统在处理TB级数据时的稳定性与准确性。
三、技术架构与实现
系统基于微服务架构,主要技术栈包括:
- 数据存储:使用Hadoop HDFS和NoSQL数据库(如MongoDB)存储原始数据,配合关系型数据库(如PostgreSQL)管理元数据。
- 数据处理:利用Apache Spark进行分布式数据清洗、转换与计算,支持实时流处理(如Kafka)与批处理结合。
- 分析与算法:集成Python/R库(如Scikit-learn、TensorFlow)实现探查算法,并通过容器化(Docker)部署,确保可扩展性。
- 前端展示:采用React或Vue.js构建响应式Web界面,结合D3.js或ECharts实现动态可视化。
四、应用场景与价值
该应用程序可广泛应用于网络工程领域:
- 运维监控:实时探查网络性能指标,自动发现瓶颈或故障根因,减少平均修复时间(MTTR)。
- 安全分析:通过行为模式发现,识别潜在入侵或异常访问,提升网络安全防护能力。
- 容量规划:基于历史数据趋势探查,预测带宽需求与设备负载,辅助资源优化决策。
实践表明,该系统能帮助团队将数据探查效率提升60%以上,并降低人为错误风险。
五、挑战与未来展望
开发过程中面临数据隐私、计算资源调度及算法精度等挑战。我们将深化AI集成,实现更智能的自动化发现;探索边缘计算部署,以应对分布式网络环境的数据处理需求。
###
通过融合火龙果软件工程的敏捷理念与先进的大数据技术,开发数据探查与发现应用程序,不仅能赋能网络工程团队从海量数据中提取关键洞察,更推动了行业向数据驱动运维的转型。这一实践为构建更智能、可靠的网络基础设施奠定了坚实基础。
如若转载,请注明出处:http://www.5gshishanglianmeng.com/product/70.html
更新时间:2026-06-18 07:02:00